- Published on
- |0|
Engineering the Recruitment Automation System
- Authors

- Name
- Abhishek Shree
- @Abhishek
The work is done for Students' Placement Office, IIT Kanpur.
Leave a star if you appreciate the work :P
Assessing the Problem
It started back in December 2021 when I got to work and improve the existing recruitment portal. We ran several security, stress, performance, and scalability tests on the portal. As a result, several vulnerabilities and performance issues were found. The was pretty well built to serve its purpose in 2014, but times have changed. We cannot have a deprecated Django version on the server sending complete HTML pages on API calls now. Moreover, operating on one thread with blocking synchronous requests, like emailing and zipping files would have never improved the performance.
Our Solution
I along with Harshit Raj figured out the exact process of recruitment and tried to simplify it. For our product we discussed multiple backend architecture possibilities and finalized a microservices-based arch having 9 microservices and a Relational Database Model, more on that in the next section. Along with independent primary services like managing a recruitment phase, students, proformas and applications, we also implementated an asychronous emailing service, a CDN for the resume storage, and zipping service with caching. Kept the frontend completely independent from the backend. We also ensured a rigourous multi-staged logging system on the backend and the Nignx reverse proxy.
Technologies used on the backend include, go, gin, gorm, postgres, jwt, along with a context-based model throughout the system. On the frontend, we used Next.js, TypeScript, Zustand, Material UI, along with several dev tools like Eslint and Prettier.
We ensured that the codebase is modular, consistent, and idiomatic throughout.
Architecture
The complete product architecture can be broadly dividied into these parts:
The Backend
The backend was implementated keeping in mind a context-based model which allows us to pass request-scoped values, cancelation signals, and deadlines across API boundaries to all the goroutines involved in handling a request. We used gin as the HTTP framework and gorm as the ORM. The databases were designed keeping in mind the independence of each microservice. We used a total of 5 databases loosely tied to each other with keys to link them together. Indexes were used appropriately to make the queries faster. We had to use extensive joins to filter out data relevant to the end users, even across databases sometimes.
We ensured panic recovery and error handling throughout the backend. Another important aspect was to keep logs of every important action performed at the admin end, so that we could track them back if needed, and also, to keep a record of the backend performance.
Let's look at another interesting design choice by this example, instead of assigning students to different sets of events available for a certain job position (say resume verification, GD, etc.) we chose to go for a model with unique events for every job position and mapping it uniquely to the students. A very neat way to convert an obvious looking NoSQL looking model to a relational one.
CDN
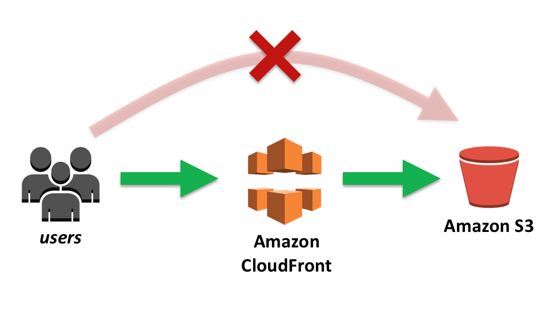
Another significant aspect of making the backend robust was to separate the logic to serve static files from the main server. We approached for the solution of this problem by considering the usage of AWS S3 along with a CloudFront CDN initially to serve the files efficiently.
 AWS based CDN
AWS based CDNBut this approach had a few drawbacks and a major blocker in our use case. A drawback was the lack of any computational power at the file server which left us with no option to compress a bunch of files based on our needs. The blocker was the recurring cost to be paid as the AWS charges, which our team was not capable of paying.
Under these circumstances, we decided to set up a local server independent of the backend within the VM itself to serve the files. This saved us around 30,000 INR per year and a redundant zipping service.
The primary idea was to leverage the context-model used (it is really powerful) and leverage the fact that file sharing via HTTP works over a TCP connection. This enabled us to cache the files shared on browser, cancelation of request in case of reload, failure, and a security on the exposed folder to prevent unauthorized access. Zipping process is carried out asychronously and the zipped file information is cached to be reused if needed. This level of caching is definitly not at par CloudFront, but yeah meets our requirements pretty well and saves quite a lot of money.
Deployment
While deploying the complete backend, Nginx was used as the reverse proxy and the complete backend was deployed over a Docker swarm. Deploying the backend was pretty challenging in itself as we had a lot of dependencies all along.
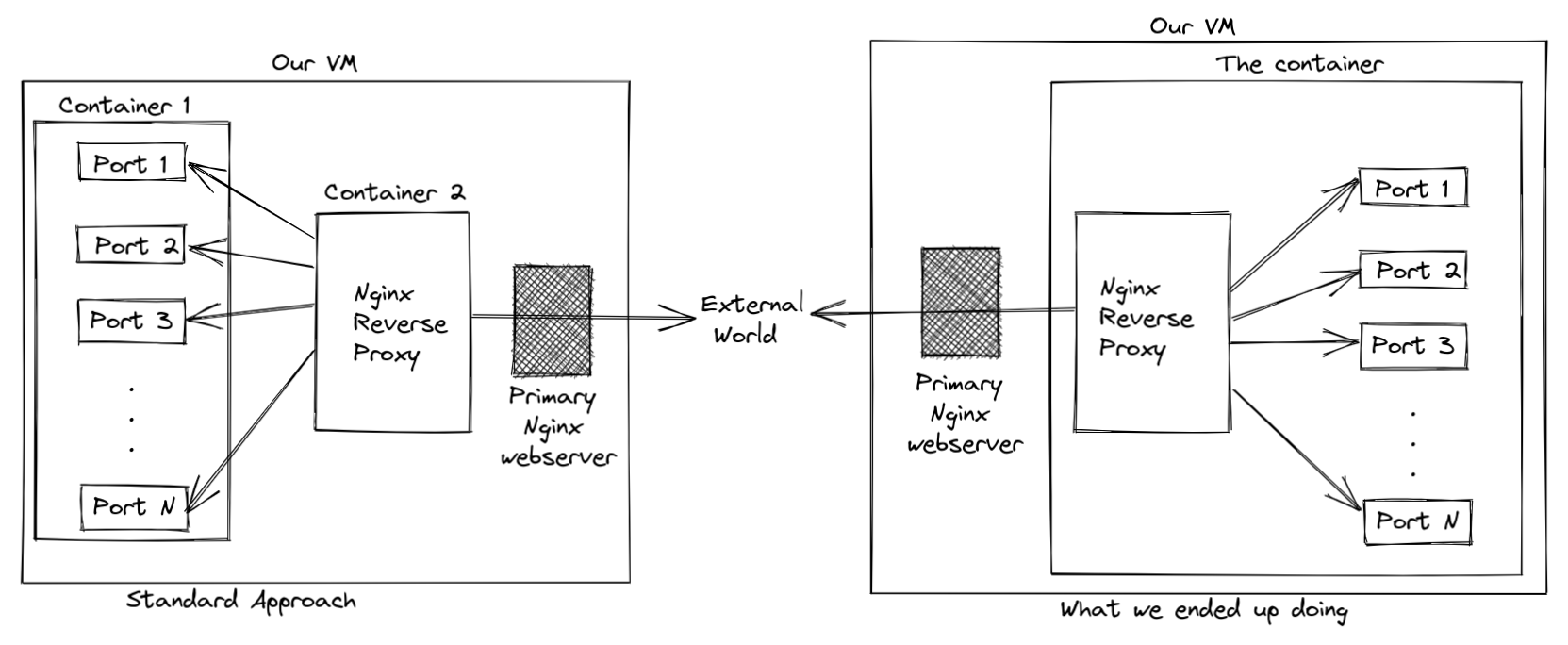
In a standard practice of deploying a backend over Nginx as the reverse proxy, it is a standard to use all the exposed ports of the backend in the VM first and then proxy the ports on the VM via Nginx. We didn't want that, imagine having 9 ports open on the VM just to proxy them on the Nginx server.
Instead, we accepted the cost of having a bit heavier Docker image for the backend, started the backend on the image, along with Nginx exposing just one port from the VM. Voila!
Frontend
We built the frontend to be at par with the backend. Keeping in mind the responsiveness, SEO and a modern UI design, we decided to use Next.js as the frontend framework. We used TypeScript, Zustand, Material UI, and several dev tools like Eslint and Prettier along the way.
To mention some of the key features of our frontend, we have:
- Type-Based API calls.
- Method to filter and export data.
- A real time update and notification system.
- A persistent global state.
- Lazy Loading for heavy components.
- Page-level authorization and layout.
- RTE Support
- Consistent Global Theming.
- We're also parsing the program-department data optimally using a bit vector directly on the frontend.
Overall it has been a pretty decent upgrade from what we had previously.